* 생존분석(Survival Analysis)라는 것은 무엇인가...?
명칭에서도 짐작할 수 있듯이 어떤 사건(event)가 발생할 때 까지의 시간에 대한 확률을 구하는 방법이 생존분석이다. 즉, 어떤 질환을 가진 경우 치료법에 따라 이환기간이 어떻게 달라지느냐..혹은 평균 생존기간(mean survival time)이 어떻게 되는지...를 알아보는게 바로 생존분석이다. 뭐...쉽게 생각하면 그 질병을 가진 집단을 조사해서...몇년 살았는지 조사해서..그냥 평균을 내면 되지 않겠냐고 할 수도 있다. 하지만...이 데이터의 특성을 가만히 생각해보면...수년간 혹은 수십년간 환자를 추적조사해야 하고...환자들 마다 사망을 하게되는 원인이 그 질병 자체일 수도 있고..혹은 교통사고와 같이 전혀 관계 없는 경우도 있으며...게다가..중간에 환자의 추적이 불가능해져서..loss되는 경우도 있겠고..어떤 경우에는 관찰기간동안 이 사건(사망)자체가 발생 안 할 수도 있다. 이렇게 많은 변수가 존재하게 된다. 이 복잡한 것들을 모두 고려해야만 좀더 정확한 생존분석이 가능할 것이고...따라서 단순히 평균이 아닌 생존분석이라는 분야가 따로 생기게 된 것이다.
물론 어떤 사건(event)라는 것은 단순히 사망만을 말하는 것은 아니다. 예를 들어 이식한 심장의 정상 작동 기간이라던지, 혹은 금으로 치아를 해넣은 경우 평균 사용기간이라던지, 혹은 어떤 기계의 수명이나, 심지어 2000년대에서 20대 남자들의 평균 연애기간은 얼마나 되는지..등등의 분석이 모두 사건으로 지칭되어 생존분석을 통해 이루어 질수 있다. 즉....어떤 사건이 일어날때까지의 시간이 모두 생존분석에 사용 될 수 있다는 것이다.
그럼..위에 언급한대로 생존분석에 포함되게 되는 여러가지 자료의 형태를 한번 살펴보자.
가장 이상적인 경우는 어떤 사건이 발생한 시점(initial event)가 정확하고, 이후 관찰기간내에 사망하는 경우(subsequent event)가 되겠다. 그러나 모든 데이터는 관찰기간동안 다 이렇지는 않을것이다. 즉, 사건의 발생과 사건이 종료되는 시점이 애매한 경우 이런 자료를 중도절단된 자료(censored data)라고 하며 생존분석에서 반드시 고려되는 점이다. 다시말하면 censored data는 환자가 관찰기간이 끝날때 까지 살아있거나, 혹은 중간에 추적이 불가능해지는 경우가 해당이 된다. 환자가 관찰기간이 끝날때 까지 살아있다면 그 환자의 경우에는 이후에 어떤 일이 발생할지 알 수 없는 경우가 되며, 추적이 안되는 경우이거나 환자가 치료를 중단하는 경우에도 마찬가지 일것이다. 또한 만약 환자가 질환과 관계없이 사망한 경우도 이에 해당되게 된다. 예를 들어 좌심실 보조기구를 장착한 환자에게서 이 장치의 사용기간을 알아보려 했는데 환자가 폐렴에 의해서 사망했다면 이 환자의 경우 사망하는 시점까지 좌심실 보조기구는 정상작동하였으므로 censored data로 간주하여야 한다. 만약 이 경우 환자의 생존율을 연구대상으로 했다면 이 데이터는 event(사망)으로 간주하나 좌심실 보조기구의 수명을 계산할때는 censored data가 된다는 것이다.
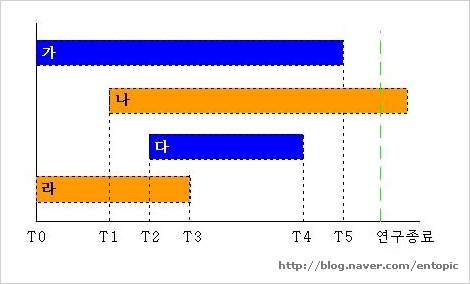
위의 그림을 보면 조금 더 이해가 갈까....
가의 경우에는 적절하게 데이터가 종료된 것이다. (Complete data, event로 coding)
나의 경우에는 연구가 종료된 시점에도 생존한 경우로 Censored data로 처리되며, 다의 경우에는 연구가 시작된 이후 포함되었다가 연구종료전에 사망한 경우로 lete data이다. 라는 연구기간동안에 follow up이 loss된 경우로 censored data로 처리한다. 각각의 생존기간은 가는 T0~T5, 나는 T1~연구종료까지, 다는 T2~T4, 라는 T0~T3이 된다.
대강의 개념은 잡힐까...^^
이렇게 censored data의 여부를 잘 알아야 자료를 구분해서 생존분석시에 이용하게 되므로, 연구시에 몇가지 주의를 해야 한다. 먼저 생존시간의 시작점(Stard Pont)의 개념을 정확하게 해둬야 하며, 확실하게 생존기간을 기록 할 수 있는 기준을 세워야 한다. 또한 이 생존기간과 비슷한 이야기지만 event의 발생여부를 확실하게 할 수 있어야 한다.
자...이제 생존분석에 사용되는 데이터의 개념은 잡았다고 치고...어떤 방법으로 생존분석이 시행되는지 알아보자. 지금까지 공부해왔던 많은 회귀분석 모델들이 그렇듯이 생존분석도 어떤 공식을 도출하는 방법과 유사한 방법으로 진행된다. 즉....어떤 수학식이 하나 얻어지며 이 수학식에 대해서 확률적 검증을 시행하게 된다. 이 방법으로 많이 들어본것이 바로 Kaplan-Meier survival analysis가 한 종류이다.
우선은 복잡한 것은 제외하고...기본개념부터 차근차근 잡아보자.
생존분석이라는 이름이 있는것처럼 생존함수(survival function)이라는 공식이 있다. 이는 censored data가 없다는 가정하에서 다음과 같이 간단하게 정의된다.

이 값은 일정 시점(t시점)에서 사망하지 않고 생존할 확률이 된다.
하지만 실제 생존분석에서 사용되는 데이터는 간단하지 않고 censored data가 포함되게 되므로 더 복잡한 과정을 거치게 된다. 그 종류로는 다음과 같이 있다.
1) Parametric model(모수적 모형)
- Exponential distribution
- Weibull distribution
- Log-normal distribution (Log-logistic distribution)
- Gamma distribution
- Rayleigh distribution
- Pareto distribution
2) Nonparametric model (Descriptive survival analysis)
- 생명표법 (Life table method, Actual method, Cutler-Ederer method)
- Kaplan-Meier method (Product limit method)
- Cox propotional hazard model
많다....복잡해 보인다....
뭐...주특기인 복잡한 것은 다 건너뛰고 필요한 몇가지만 알고 넘어가자.
대부분 환자를 대상으로 하는 연구는 모수적 검정을 거치기에는 그 수와 기간이 상당히 필요하기 때문에 특정한 분포를 한다고 생각하는 모수적 검정방법을 적용하기엔 무리가 따른다. 따라서 비 모수적 검정을 많이 사용하게 되며 이 방법은 어떤 사건의 결과 즉, 생존하는지 사망하는지 등을 종속변수로 간주하고 어떤 시점에서 생존률과 평균생존률을 구하여 두 결과의 차이가 있는지를 비교하는 방법이다. 오오....정말 누군진 몰라도 머리가 좋다....^^
이 방법중에서 의학분야에서 많이 사용되는건 위에 나열된 세가지 (생명표법, Kaplan-Meier method, Cox propotional hazard model)이 있으며 SigmaStat에서는 Kaplan-Meier method를 제공하고 있다. SPSS 12버전의 경우에는 위 세가지 모델이 모두 제공되므로 필요할때는 SPSS를 더 공부해보면 되겠다. 어찌하였든, 세가지 모델의 장단점이 있으므로 언제 무엇을 해야할지 정도는 조금 알아보고 넘어가는게 좋을듯 싶다.
우선 생명표법을 사용하는 방법은 생존기간이 비교적 짧은 질환(5~10년정도)을 대상으로 연구기간의 설정을 몇년 몇월 몇일단위로 명확하게 설정 할 수 있는경우에 해당이 된다. 또한 이 방법은 진짜로 어떤 구간에서 생존률을 구해서 계산하는 방법이므로 관측대상의 수가 많아야 비교적 정확한 결과를 얻을 수 있다. 그렇기 때문에 censored data가 발생하는 경우에는 분석의 기간을 짧게 쪼개서 5년 survival rate, 10년 survival rate등으로 구해서 그 기간에 censored 되는 경우를 제외할 수 있도록 하는 방법을 사용해야 한다. 그러나..이 방법을 사용하게 되면 될 수록 실제 survival과 점점 더 먼 결과를 얻게 될 것이다. 또한 생명표법을 이용하는 데이터는 연구가 진행되는 동안에는 이 집단에서 생존률에 결정적인 영향을 주는 인자가 없어야 한다는 것이다. 예를들어 난치병인 경우에 획기적인 치료방법이 개발되어 생존률에 영향을 준다면 그 경우의 전후에 걸쳐서 생명표법을 사용할 수 없다는 것이다. 조금 뜬구름 잡는 듯한 이야기지만 얼추..어떤 내용인지는 짐작이 되리라...--;;
Cox proportional hazard model은 logistic regression을 사용해서 censored data를 처리하는 방법이다. 즉, 생존에 영향을 주는 많은 인자들(성별, 분석당시의 나이, 지병등)에 대한 고려를 해서 회귀분석을 시행하는 것이다. 앞에 설명된 생명표법이나 뒤에 설명될 Kaplan-Meier method의 경우 이와같은 인자들에 대해 고려를 하지 않는다는 단점이 있다. 따라서 이런 인자들을 고려해서 이것들이 동시에 생존시간에 영향을 주는 정도를 알아보기 위해서 일반적으로 받아들여 지는 모델이 Cox가 제공한 비례위험 회귀모형(proportional hazard model)이다.
Kaplan-Meier method는 데이터의 생존기간을 짧은 순서에서 긴순서로 나열하여 어떤 event(사망)이 발견된 시점마다 생존확률을 계산하는 방법이다. 즉, Product limit method라고도 불리게 되는게 바로 이 이유이다. 이 방법은 생명표법과 다르게 일정한 간격으로 관찰기간을 일정하게 나누는게 아니라 event가 발생할 때 마다 관찰시간의 간격이 불규칙적으로 나누어 지게 되므로 표본의 수가 적은 경우 (일반적으로 50개 미만)에 유용하게 사용할 수 있다.
이와같은 Kaplan-Meier method나 생명표법은 어떤 event가 발생했는가 아닌가에 중점을 두고 분석을 하므로 위에 설명된 것과 같이 이 event가 발생에 영향을 주는 변수들에 고려가 없다는것이 단점이다.
일단 SigmaStat에서 제공하는 생존분석의 방법은 Kaplan-Meier방법밖에 없으므로 이 방법을 다음 글에서 먼저 공부하고 추후에 SPSS를 통해서 Cox proportional hazard model을 알아보기로 하자.
지금까지 개념을 알아온 것은 어떤 한 집단에서 생존분석을 하는 방법이었다. 그럼 어떤 두 집단에서 생존의 양상을 비교하기위한 방법으론 무엇이 있는지 알아보자.
일단 두 집단의 생존분석 결과 (생존의 확률)을 비교하면 별 문제없지 않을까..생각이 든다. 하지만 이게 정말 통계적인 차이를 보이는지 검증을 하는게 역시 필요할 것이다. 이를 위해서 제시된 비교방법이 여러가지가 있다.
- Mantel_Haenszel method
- Log-Rank method (Mantel-Cox)
- Gehan's generalized Wilcoxon method (Breslow test)
- Likelihood ratio
뭐..여지껏 여러가지 통계기법들을 살펴봐 오면서 느낀거지만 꼭 비모수적 방법들에만 저렇게 복잡한 이름들이 붙는다. 아니나 다를까 위에 제시된 방법들은 대부분이 비모수적 방법이다. 왜 하필 복잡한 비모수적 방법을 사용하는 것일까...?
대부분의 임상자료들은 정규분포를 따라서 생존분포를 이루는게 아니라 특정한 이론적인 생존분포를 따라간다고 한다. 즉....평균값이 아니라 중앙값을 사용하게 된다. (내과학 책을 상펴보면 mean survival time이라는 말보다 median survival time이라는 말을 자주 접하게 된다.) 즉....비모수적 방법을 사용해야 된다는 의미가 된다. 그렇다는건 대충 이해가 간다.
만약 어떤 두 집단에서 생존률을 비교할때 단순히 어느 한 시점에서 생존률을 비교하는 방법은 전체 관찰기간을 통한 비교가 아니므로 사실과 다른 결과를 도출 할 수 있다. 그렇기 때문에 전체적인 생존함수의 비교가 이루어 져야 한다. 즉, 어떤 실험을 하면서 일정간격으로 데이터를 얻었다면 이들의 전체적인 변화는 RM ANOVA를 사용해서 결과를 분석하게 된다. 하지만 만약 한 시점에서 두군의 차이를 비교하기 위해 paired T-test를 사용한다면 총괄적인 변화가 아닌 일시적인 현상일 수 있으므로 잘못된 결과를 이끌어 낼 수 있다는 것이다.....뭐..그렇단다..아직은 확실하게 이해되지 않지만...이후에 더 잘 이해할 수 있으리라 생각하고 일단은 넘어가겠다..--;;
일단은 SigmaStat에서 제공하는 방법은 Log-Rank test와 Gehan-Breslow method이므로 이 방법들은 각각 추후에 알아보기로 하자.
'MIS' 카테고리의 다른 글
| [SAS] 다차원척도법 - 1 (0) | 2009.11.20 |
|---|---|
| 다차원척도법 (0) | 2009.11.20 |
| ADSL 서비스 상용화 10주년 (0) | 2009.11.04 |
| 아이폰이 과연 생각만큼 많이 팔렸을까? (0) | 2009.11.02 |
| 애플, 2008년 4쿼터 아이폰 판매량 발표와 3G 아이폰 가능 국가 지도 (0) | 2009.11.02 |
댓글